
En este artículo, estudiaremos uno de los Mulesoft Anypoint Connectors, Apache Kafka, el cual te permite interactuar con el sistema de mensajería de Apache Kafka y ofrece una integración fluida entre tus aplicaciones Mulesoft (Mule) y el cluster de Apache Kafka a través del motor de ejecución de Mule.
Este documento asume que estás familiarizado con Apache Kafka, Mule, Anypoint Connectors y Anypoint Studio Essentials.
Seguiremos el siguiente índice:
|
1. Introducción
Las plataformas de integración ofrecen un amplio abanico de conectores out-of-box (OOTB) que permiten que las empresas conecten sus aplicaciones a otras fuentes de datos. Los conectores unifican ecosistemas empresariales enteros y solucionan casos de uso de integración complejos. Abstraen los detalles técnicos relacionados a la conexión con un sistema meta.
Una empresa normalmente necesita conectores para enviar o recibir datos de aplicaciones/fuentes de datos o para conectarse a una aplicación específica a través de un protocolo en particular e intercambiar datos por medio de un formato determinado. La mayoría de los proveedores de plataformas de integración en el mercado ofrecen conectores OOTB que están disponibles de inmediato a través de su centro o repositorio.
Mulesoft tiene conectores Anypoint que sirven como extensiones reutilizables al motor de ejecución de Mule que te permite integrar la aplicación de Mule a APIs, bases de datos y protocolos de integración estándares de terceros.
1.1. Casos de uso asociados
- Agregación de registro – Aprovecha el procesamiento de latencia baja de Kafka para recabar registros de múltiples servicios y ponerlos a disposición de múltiples consumidores en un formato estándar.
- Análisis y parámetros – Optimiza tu presupuesto publicitario al integrar Kafka y tu solución analítica de grandes volúmenes de datos para analizar la actividad del usuario final, como las visitas de páginas, los clicks, las veces compartidas, etc., y así poder posicionar publicidad relevante.
- Notificaciones y alertas – Notifica a los clientes sobre una gran variedad de eventos financieros, desde la suma de una transacción reciente, a eventos más complejos, como sugerencias de inversiones futuras basadas en integraciones con agencias de crédito, su ubicación, etc.
2. Componentes necesarios para configurar Apache Kafka con Mulesoft
A continuación explicaremos los componentes necesarios para configurar Apache Kafka con Mulesoft.
- Apache Kafka
Apache Kafka es una plataforma de streaming de eventos distribuida y de código abierto que emplean miles de empresas como conducto de alto rendimiento, para el análisis de streaming, la integración de datos, y para aplicaciones decisivas. Tiene una alta disponibilidad, es resistente ante los fallos de nodos y apoya la recuperación automática. Apache Kafka implementa hilos robustos que manejan un alto volumen de datos y cuenta con un activador que transfiere los mensajes desde un endpoint a otro. Apache Kafka sirve tanto para el consumo de mensajes en línea y fuera de línea.
Apache Kafka está construido sobre el dispositivo de sincronización de Apache ZooKeeper™. Todos los mensajes de Kafka están organizados por hilos.
- Mulesoft Apache Kafka Connector
El conector Anypoint de Mulesoft para Apache Kafka te permite interactuar con el sistema de mensajería de Apache Kafka, por lo que conseguirás una integración fluida entre tu aplicación de Mule y el cluster de Kafka. Satisface la necesidad del cliente de Mulesoft que busca una manera intuitiva de integrar con Apache Kafka y así crear productores, consumidores y operaciones de envío y de recepción de mensajes.
- Mule Design-time: Anypoint Studio
Anypoint Studio es el entorno de desarrollo integrado (IDE) de Mulesoft para los proyectos de integración. Permite que las organizaciones creen y gestionen servicios, y capturen y publiquen eventos de aplicaciones y tecnologías tanto internas como externas. Los desarrolladores pueden fomentar, y probar rápida y gráficamente los procesos en un IDE sin código y basado en estándares. Después despliegan estos procesos en una arquitectura fiable, altamente disponible y escalable para ofrecer apoyo a aplicaciones decisivas.
- Apache Kafka palette
El Apache Kafka palette sirve para crear productores y consumidores, y para llevar a cabo operaciones de envío y recibo de mensajes. El plug-in ofrece las siguientes funciones principales:
- Publicar, consumir
- Receptor del mensaje
- Receptores en grupod el mensaje
- Commit y Seek
2.1 Versiones necesarias
- Java [Ver. 1.8] Descargar
- Mule Design-time: Anypoint Studio [Ver. 7.8.0]: Descargar
- Mule Run-time [Ver. 4.3.0 EE]: Descargar
- Mulesoft Connector for Apache Kafka [Ver. 4.4.x] Descargar
- Apache Kafka [Ver. 2.7.0]: Descargar
3. Arquitectura general
La siguiente figura describe la relación entre el Apache Kafka Server, el Mulesoft Connector para Apache Kafka, el Mulesoft Anypoint Studio y CloudHub.
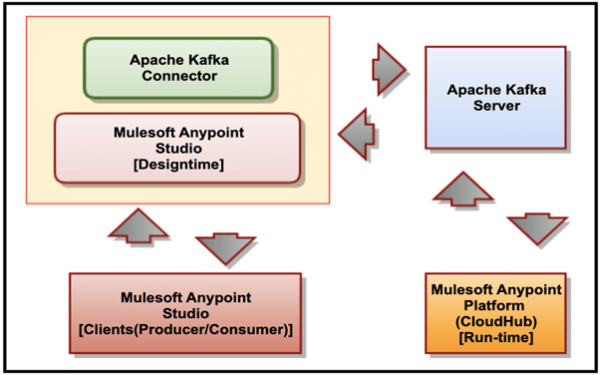
La lista describe la relación entre los distintos productos:
- Mulesoft Connector para Apache Kafka se enchufa a Mulesoft Anypoint Studio y se conecta a una instancia del servidor de Kafka.
- Mulesoft Anypoint Studio es la interfaz gráfica de usuario (GUI) que emplea Mulesoft Anypoint Studio y el plug-in para los procesos de empresa de diseño. También es el motor de proceso que se emplea para ejecutarlos.
- Mulesoft Anypoint Platform (CloudHub) ofrece una interfaz administrativa y centralizada para gestionar y supervisar las aplicaciones plug-in desplegadas en una empresa. (Este componente se sale del ámbito del presente artículo).
4. Instalación y configuración de Apache Kafka Connector
Añade el Anypoint Connector para Apache Kafka (Apache Kafka Connector) en Anypoint Studio al proyecto Mule, configura la conexión al cluster de Kafka, y configura una fuente de salida para el conector.
Requisitos
Antes de crear un app, deberás:
- Tener acceso al recurso meta de Apache Kafka y a Anypoint Platform.
- Entender cómo crear una aplicación de Mule con Anypoint Studio.
- Tener acceso a Apache Kafka para obtener los valores para los campos que aparecen en Studio.
4.1. Cómo añadir el Connector en Studio a través de Exchange
Estos son los pasos que deberás seguir para añadir el conector:
1.Crea un proyecto Mule en Mulesoft Anypoint Studio.

2. Pulsa en «Search in Exchange» en el Mule Palette. Teclea el nombre del conector en el campo de búsqueda «kafka» y pulsa «Enter».

3. Pulsa sobre el nombre del conector en «Available modules».
4. Pulsa en «Add» para incluir lo mismo en «Selected modules» y luego pulsa en «Finish».

5. Ahora veremos el módulo de Apache Kafka y las respectivas actividades en Mule Palette.

6. Ahora podemos crear un flujo de proceso.
5. Flujo de proceso para publicar y consumir un mensaje
Ahora desarrollaremos dos flujos de proceso en Mule Anypoint Studio; uno de ellos tendrá un publicador de mensaje que publicará en Kafka Topic, y otro tendrá un suscriptor que recibirá el mensaje publicado en el mismo hilo.
5.1 Configuración del recurso compartido por los consumidores
1.Crea un elemento de configuración global para los consumidores.
2. Ahora puedes crear un elemento de configuración global para consumidores al que referenciar desde el Apache Kafka Connector. Esto te permite implementar detalles de configuración a múltiples elementos locales en el flujo.
3. Pulsa sobre Global Elements en Studio.

4. Pulsa en «Create» y expande la configuración del conector.
5. Selecciona la configuración de Apache Kafka Consumer y pulsa en OK.
6. En el campo de conexión, selecciona un tipo de conexión.

7. Ahora confirma la conexión con Kafka Server y pulsa sobre el botón «Test Connection».
* Cuidado – Kafka ZooKeeper y Kafka Broker deben estar ejecutados para que esto funcione.

5.2 Configuración del recurso compartido por los productores
1.Ahora crearemos un elemento de configuración global para productores del mismo modo que lo hicimos para consumidores en el paso anterior.
2. Ahora puedes crear un elemento de configuración global para productores al que referenciar desde el Apache Kafka Connector. Esto te permite implementar detalles de configuración a múltiples elementos locales en el flujo.


Ahora crearemos flujos de proceso de productor y consumidor usando las respectivas configuraciones de conectores creadas.
5.3. Flujo del productor de mensaje
Ahora crearemos un flujo de proceso para publicar un mensaje en Kafka Topic a través de la actividad de Kafka Publish.
1. Crea un flujo de proceso sencillo para el publicador del mensaje como se muestra a continuación:

2. HTTP Listener recibirá a través del enlace http://localhost:8081/kafka.

3. Rellena el nombre del hilo y sitúalo en la actividad Publish tal y como se muestra a continuación:

5.4. Flujo del consumidor de mensajes
Ahora crearemos un flujo de proceso para recibir un mensaje del Kafka Topic a través de la actividad de Kafka Listener.
1.Crea un flujo de proceso sencillo para el consumidor del mensaje como se muestra a continuación:

2. Crea una conexión de consumidor de Kafka con los detalles especificados.

6. Probar para confirmar el E2E Process Flow
Ahora probaremos los flujos de proceso a través del proceso del publicador, que recibirá un mensaje del usuario y lo publicará en Kafka Topic. El flujo de proceso del suscriptor, que recibe en el mismo hilo, recibirá el mensaje que ha enviado el usuario.
1. En primer lugar, inicia el proceso en modo debug y abre la URL en un navegador web, como se muestra a continuación.

2. Esto iniciará el flujo de proceso de Mulesoft Publisher y a actividad de Kafka Publish publicará un mensaje en el hilo «test».

3. La actividad de Kafka Consumer consume el mismo mensaje, que se registrará en la consola.
./kafka-console-consumer.sh –topic test –from-beginning –bootstrap-server=localhost:9092

4. Verás el mismo mensaje suscrito en el hilo «test» con el flujo de proceso del consumidor.

5. La actividad quedará registrada con el mismo mensaje en la consola, tal y como se muestra a continuación.

7. Conclusión
En este artículo hemos:
- configurado Apache Kafka y Kafka Connector con Mulesoft
- creado un cliente consumidor que recibe un determinado hilo en Apache Kafka
- creados dos flujos de proceso:
- un emisor de mensaje que publica un mensaje en el hilo «test»
- un receptor de mensaje que ve el hilo «test»,
- finalmente, hemos recibido el mensaje del consumidor de Kafka que leía el hilo «test».





