
Dans cet article, nous aborderons l’un des connecteurs Mulesoft Anypoint, Apache Kafka, qui vous permet d’interagir avec le système de messagerie Apache Kafka et garantit une intégration fluide entre vos applications Mulesoft (Mule) et un cluster Apache Kafka à l’aide du runtime Mule.
Ce document est destiné à des lecteurs familiers des systèmes Apache Kafka, Mule, des connecteurs Anypoint et des fondamentaux Anypoint Studio.
Pour cela, il convient de respecter l’index ci-dessous:
|
|---|
1. Introduction
Les plateformes d’intégration proposent une vaste gamme de connecteurs prêts à l’emploi qui permettent aux entreprises de connecter leurs applications ou sources de données. Les connecteurs unifient l’écosystème complet de l’entreprise et résolvent des cas d’utilisation complexes en matière d’intégration. Ils omettent les détails techniques qui se cachent derrière la connexion à un système cible.
De manière générale, une entreprise a besoin de connecteurs pour envoyer ou recevoir des données provenant d’applications/de sources de données ou pour établir la connexion à une application à l’aide d’un protocole spécifique ou l’échange de données en utilisant un format de données défini. La plupart des fournisseurs de plateformes d’intégration sur le marché proposent des connecteurs prêts à l’emploi, déjà disponibles dans leur hub ou répertoire.
Mulesoft est doté de connecteurs Anypoint, des extensions réutilisables du runtime Mule, qui vous permettent d’intégrer une application Mule à des API tiers, des bases de données et des protocoles d’intégration standard.
1.1 Cas d’utilisation associés
- Agrégation des journaux : tirez profit du traitement à faible latence de Kafka pour collecter des journaux à partir de multiples services et rendez-les disponibles au format standard pour de nombreux clients.
- Analyses et mesures : optimisez votre budget de publicité en intégrant Kafka et votre solution d’analyse du Big Data pour analyser l’activité utilisateur comme les pages consultées, les clics, les partages et bien d’autres données pour proposer des publicités pertinentes.
- Notifications et alertes : informez les clients des différents événements financiers, du montant de la transaction récente aux événements plus complexes comme des suggestions de futurs investissements à partir d’intégrations d’agences de crédit, d’emplacement et bien plus.
2. Composants requis pour la configuration d’Apache Kafka avec Mulesoft
Ci-dessous, nous expliquerons les composants nécessaires à la configuration d’Apache Kafka avec Mulesoft.
- Apache Kafka
Apache Kafka est une plateforme de diffusion d’événements distribuée ouverte utilisée par des milliers d’entreprises à des fins de pipelines de données haute performance, d’analyse de la diffusion, d’intégration des données et d’applications essentielles à la mission. Elle présente une excellente disponibilité, une bonne résistance aux pannes de nœuds et prend en charge la récupération automatique. Apache Kafka contient des rubriques robustes capables de traiter un grand volume de données et dispose d’un outil capable de transmettre les messages d’un terminal à un autre. Apache Kafka est adapté à la consommation de messages en ligne et hors ligne. Apache Kafka est intégré au service de synchronisation Apache ZooKeeper™. Tous les messages Kafka sont répartis en rubriques.
- Connecteur Apache Kafka Mulesoft
Le connecteur Anypoint de Mulesoft pour Apache Kafka vous permet d’interagir avec le système de messagerie Apache Kafka en obtenant une intégration fluide entre votre application Mule et votre cluster Kafka. Il vient en réponse au besoin du client Mulesoft, qui souhaite disposer d’un moyen convivial de procéder à l’intégration avec Apache Kafka pour créer des producteurs, de consommateurs et envoyer/recevoir des messages.
- Durée de conception Mule : Anypoint Studio
Anypoint Studio est l’environnement de conception intégré de Mulesoft (IDE) pour les projets d’intégration. Il permet aux organisations de créer, d’orchestrer des services, de capturer et de publier des événements à partir de technologies et d’applications internes et externes. Les développeurs peuvent rapidement concevoir et tester graphiquement les processus d’intégration dans un environnement de développement intégré (EDI) sans code et basé sur les normes. Ces processus sont ensuite déployés dans une architecture fiable, hautement disponible et échelonnable pour soutenir les applications essentielles à la mission.
- Palette Apache Kafka
La palette Apache Kafka peut être utilisée pour créer des producteurs et des consommateurs, ainsi que pour envoyer et recevoir des messages. Le plug-in fournit les fonctions principales suivantes :
– Publier, consommer
– Listener (écouteur) de messages
– Listener de messages en lots
– Envoyer et rechercher
2.1 Versions requises
- Java [Ver. 1.8] Télécharger
- Durée de conception Mule : Anypoint Studio [Ver. 7.8.0] : Télécharger
- Durée d’exécution Mule [Ver. 4.3.0 EE] : Télécharger
- Connecteur Mulesoft pour Apache Kafka [Ver. 4.4.x] Télécharger
3.Architecture globale
La figure suivante décrit la relation entre le serveur Apache Kafka, le connecteur Mulesoft pour Apache Kafka, Mulesoft Anypoint Studio et CloudHub.
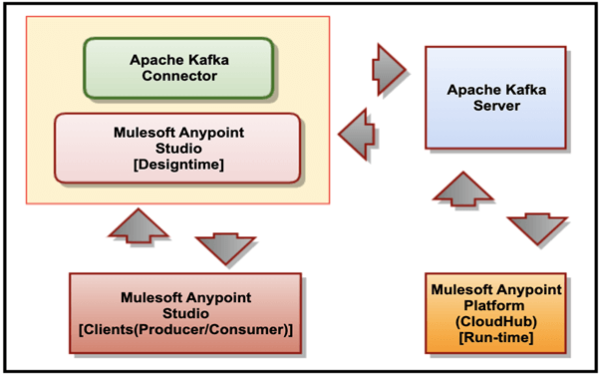
La liste suivante décrit la relation entre les différents produits:
- Le connecteur Mulesoft pour Apache Kafka s’intègre à Mulesoft Anypoint Studio et établit la connexion à une instance de serveur Kafka.
- Mulesoft Anypoint Studio est l’interface utilisateur graphique (GUI) utilisée par Anypoint Studio et le plug-in de conception de processus opérationnels; il s’agit également du moteur de processus utilisé pour les exécuter.
- Mulesoft Anypoint Platform (CloudHub) fournit une interface administrative centralisée pour la gestion et le suivi des applications plug-in déployées dans une entreprise. (Ce composant n’est pas concerné par nos discussions en cours.
4. Installation et configuration du connecteur Apache Kafka
Dans Anypoint Studio, ajouter le connecteur Anypoint pour Apache Kafka (connecteur Apache Kafka) à un projet Mule, configurer la connexion au cluster Kafka et configure une source d’entrée pour le connecteur.
Exigences préalables
Avant de créer une application, vous devez:
- Avoir accès à une ressource cible Apache Kafka et à la plateforme Anypoint.
- Comprendre la procédure à suivre pour créer une application Mule à l’aide d’Anypoint Studio.
- Avoir accès à Apache Kafka pour obtenir des valeurs pour les champs qui apparaissent dans Studio.
4.1 Ajout du connecteur dans Mulesoft Anypoint Studio à l’aide d’Exchange
Voici les étapes à suivre pour ajouter le connecteur:
1. Dans Mulesoft Anypoint Studio, créer un projet Mule.
2. Dans la palette Mule, cliquer sur « Search in Exchange » (Rechercher dans Exchange). Saisir le nom du connecteur dans le champ de recherche, « kafka » et appuyer sur « Enter » (Entrée).
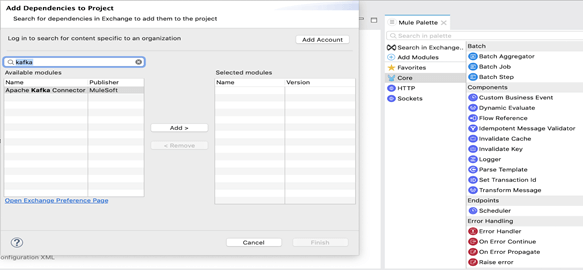
3. Cliquer sur le nom du connecteur dans « Available modules » (Modules disponibles).
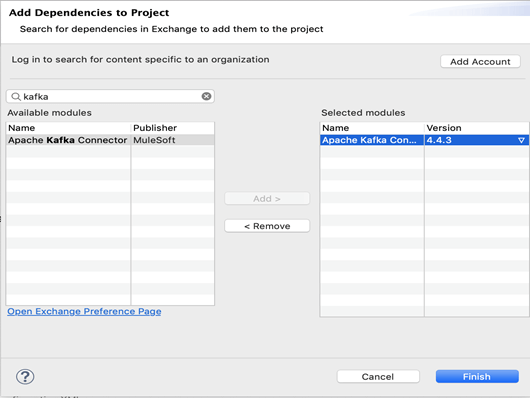
4. Cliquer sur Add (Ajouter) pour inclure le même connecteur dans « Selected modules » (Modules sélectionnés) et cliquer sur « Finish » (Terminer).
5. Nous pouvons à présent voir le module Apache Kafka et les activités respectives dans la palette Mule.
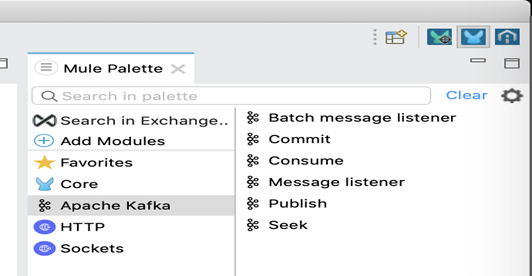
6. Nous pouvons à présent poursuivre dans la création d’un processus.
5. Processus de publication et de consommation d’un message
Ici, nous élaborerons deux processus dans Mule Anypoint Studio. Le premier disposera d’un diffuseur de message qui publiera un message sur une rubrique Kafka. L’autre disposera d’un abonné, qui recevra le message publié sur la même rubrique.
5.1 Configuration des ressources partagées avec le client
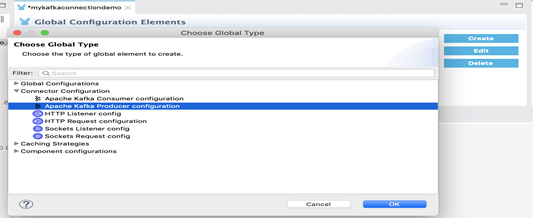
1. Créer un élément de configuration globale.
2. Vous pouvez créer un élément de configuration globale consommateur pour créer une référence à un connecteur Apache Kafka. Cela vous permet d’appliquer des détails de configuration à divers éléments en local dans le processus.
3. Sur le canevas Studio, cliquer sur les éléments globaux.
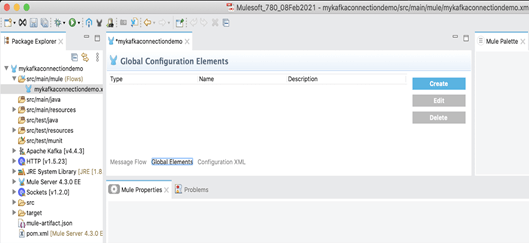
4. Cliquer sur Create (Créer) et développer la configuration du connecteur.
5. Sélectionner la configuration du consommateur Apache Kafka et cliquer sur OK.
6. Dans le champ de connexion, sélectionner un type de connexion.
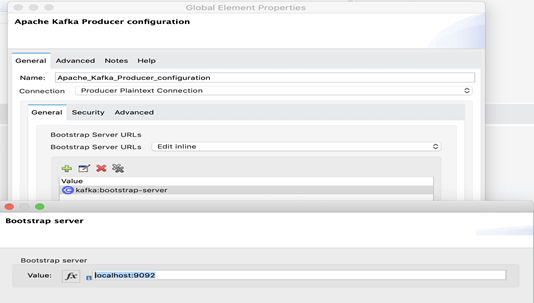
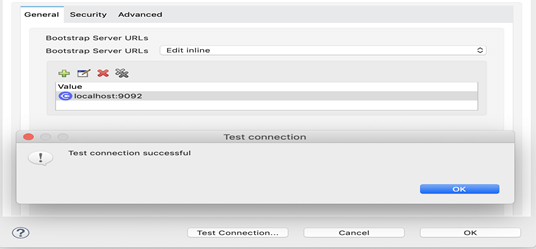
7. Puis, pour confirmer la connexion au serveur Kafka, cliquer sur le bouton « Test Connection » (Tester la connexion).
* Remarque : Kafka Zookeeper et le broker Kafka doivent être en cours d’exécution pour que cette étape fonctionne
5.2 Configuration des ressources partagées avec le producteur
1. Nous allons à présent créer l’élément de configuration globale du producteur de la même manière que nous venons de le faire pour le client lors de l’étape précédente.
2. Vous pouvez créer un élément de configuration globale producteur pour créer une référence à un connecteur Apache Kafka. Cela vous permet d’appliquer des détails de configuration à divers éléments en local dans le processus.
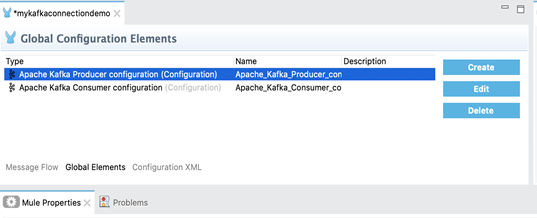
Ensuite, nous créerons des processus consommateur et producteur à l’aide des configurations de connecteur créées.
5.3 Flux du producteur de message
À présent, nous allons créer un processus visant à publier un message sur la rubrique Kafka à l’aide de l’activité de publication Kafka.
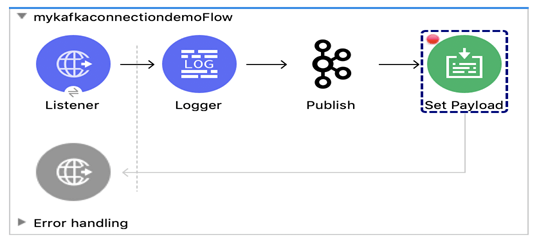
1. Créer un processus simple pour le diffuseur de message comme indiqué ci-dessous:
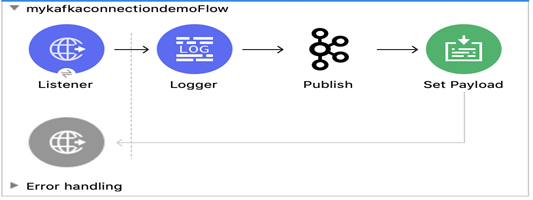
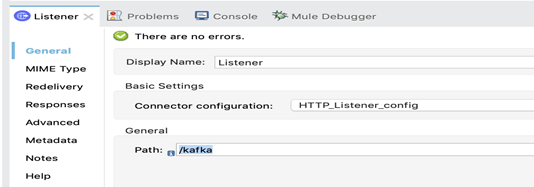
2. Le listener HTTP sera à l’écoute à partir du lien « http://localhost:8081/kafka »
3. Compléter le nom de rubrique et la charge utile dans l’activité de publication comme indiqué ci-dessous:
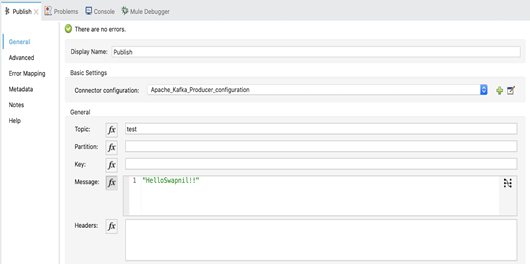
5.4 Message Consumer flow
À présent, nous allons créer un processus visant à recevoir un message provenant de la rubrique Kafka à l’aide de l’activité Listener Kafka.
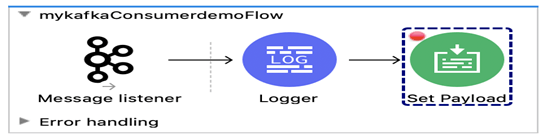
1.Créer un processus simple pour le consommateur de message comme indiqué ci-dessous:
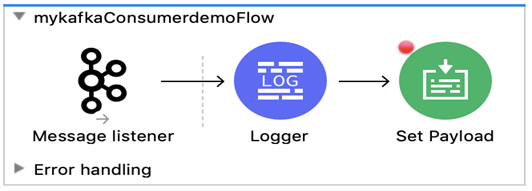
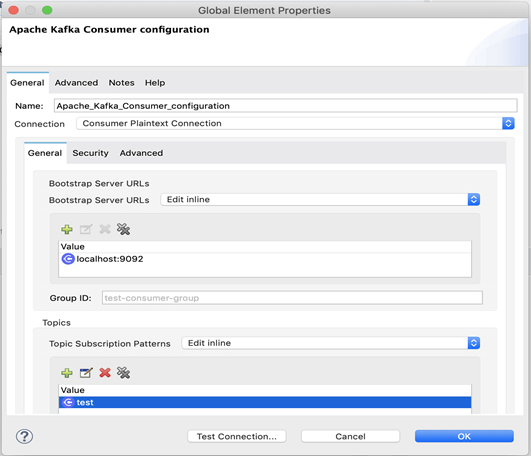
2. Créer une connexion de consommateur Kafka avec les détails indiqués.
6. Tests de vérification du processus de bout en bout
À présent, nous allons tester les processus en invoquant le processus du diffuseur, qui recevra un message provenant de l’utilisateur et le publiera sur une rubrique Kafka. Le processus de l’abonné, qui est à l’écoute de la rubrique en question, recevra le message envoyé par l’utilisateur.
1. Avant tout, démarrer le processus en mode débogage et invoquer l’URL dans un navigateur web comme indiqué ci-dessous.
2. Cela démarrera le processus du diffuseur Mulesoft et l’activité de publication Kafka publiera un message sur la rubrique « test ».
3. L’activité de consommateur Kafka consommera le même message, qui sera enregistré dans le journal de la console.
./kafka-console-consumer.sh –topic test –from-beginning –bootstrap-server=localhost:9092
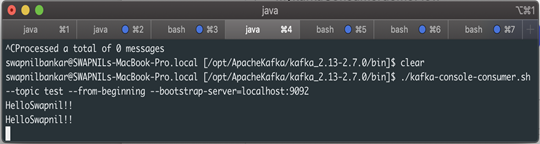
4. Grâce au processus du consommateur, vous trouverez le message faisant l’objet d’un abonnement sur la rubrique « test ».
5. L’activité sera enregistrée dans le journal avec le même message que celui de la console, comme indiqué ci-dessous.
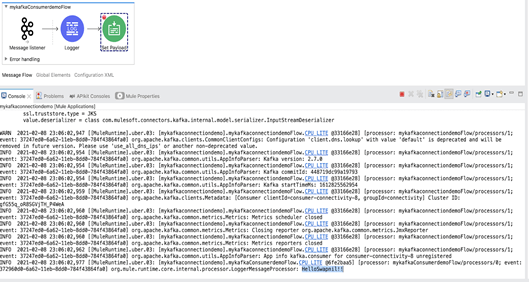
7. Conclusions
Dans le cadre de cet article, vous avez:
- Configuré Apache Kafka et le connecteur Kafka avec
- Créé un client consommateur à l’écoute d’une rubrique donnée avec Apache Kafka
- Créé 2 processus:
- envoyé un message au diffuseur pour qu’il publie le message sur la rubrique « test »
- envoyé un message au listener pour qu’il écoute la rubrique « test »
- Reçu le même message que le client Kafka, qui était à l’écoute de la rubrique « test ».





