
Hoy vamos a visualizar mediante un ejemplo gráfico cómo se implementaría una configuración combinando ambos tipos de VRRP, tanto a nivel global como a nivel de entorno, para lograr un equilibrio entre alta disponibilidad y escalabilidad en Nginx mediante Keepalived.
1. VRRPs entre CPDs
1.1 ¿Qué es el VRRP (Virtual Router Redundancy Protocol?
El VRRP (Virtual Router Redundancy Protocol) es un protocolo de red diseñado para proporcionar redundancia de router en una red. Es utilizado para asegurar que una dirección IP específica siempre esté disponible en una red, aunque un router falle o se desconecte. Para lograr esto, se utilizan varios routers que trabajan juntos para compartir la carga de enrutamiento y mantener la conectividad en caso de fallo de uno de ellos. Un protocolo de comunicaciones no propietario diseñado para aumentar la disponibilidad de la puerta de enlace por defecto dando servicio a máquinas en la misma subred.
Es importante crear una infraestructura con Alta Disponibilidad, nuestros servidores ofrecen servicios sin que éstos dejen de estar operativos momentáneamente y dejen de realizar su función por fallos o por causas ajenas.
1.2 Tipos de IP Virtual: Escenarios realizados para la configuración
Se pueden definir 2 o más IP virtuales en la misma máquina. A continuación vamos a mostrar uno de los escenarios que hemos realizado con este tipo de configuración.
- Una VRRP global donde incluye todos los load balancers de cada entorno. En caso de falla de uno de los load balancers, el tráfico sería redirigido automáticamente a otro load balancer activo en cualquier entorno. Esta configuración proporciona un mayor nivel de tolerancia a fallos y una mejor capacidad de recuperación ante fallos, ya que el tráfico puede ser redirigido a cualquier entorno activo independientemente del CPD en el que esté.
- Una configuración de VRRP por entorno, es similar a la configuración global, pero se limita a un solo entorno específico. En este caso, solo se configurarán los dos load balancers de ese entorno para trabajar juntos como un grupo de alta disponibilidad. Si uno de los load balancers falla, el otro tomaría automáticamente el control y se encargaría de la distribución del tráfico. Esta configuración es más limitada en términos de recuperación ante fallos, pero puede ser adecuada para entornos con una menor cantidad de tráfico o con requisitos de disponibilidad menos estrictos.
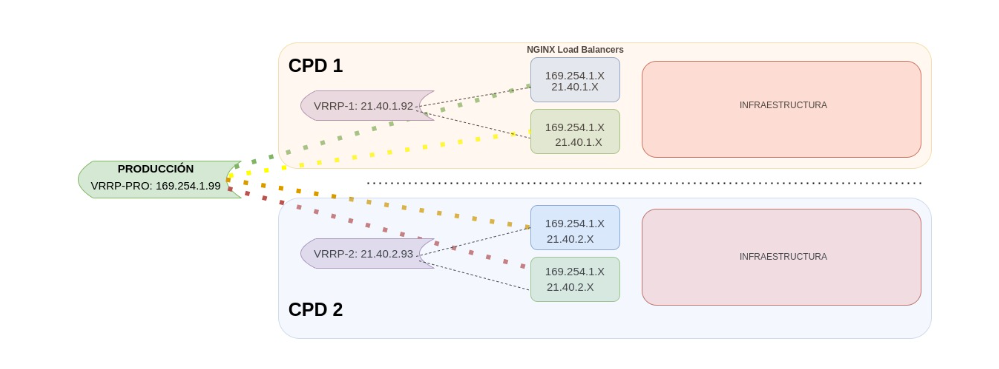
Figura 1. VRRP
Una infraestructura de este estilo es de gran utilidad para garantizar una comunicación constante en los casos en que un servidor está caído o con una gran cantidad de carga que no pueda mantener la comunicación, automáticamente nos redirige el tráfico a la segunda máquina que hemos configurado previamente.
En el ejemplo mostrado, hemos creado dos escenarios de VRRPs, en la primera donde conectamos cada uno de los Load Balancers por entorno, separando PRE y PRO, de esta manera solamente tenemos que apuntar a una sola dirección IP y está nos redirige a la máquina con mayor prioridad activa.
En la segunda creamos una VRRP por entorno y CPD, de esta manera si apuntamos a una IP virtual de este grupo, nos aseguramos que solamente puede redirigir hacia el otro Load Balancer de su mismo entorno y CPD.
2. Instalar Nginx
Instalamos Nginx y lo configuramos como un balanceador de carga, permitiendo distribuir las solicitudes entrantes entre varios servidores backend, aumentando la escalabilidad y disponibilidad de nuestros servicios.
vagrant@nginx:~$ apt install nginx
En el laboratorio, configuraremos un archivo index.html personalizado en ambos nodos, para poder identificar fácilmente cuál es el servidor que está atendiendo las solicitudes al acceder al sitio web a través de la dirección IP virtual.
En el nodo 1, ejecutaremos el siguiente comando para personalizar el archivo html:
vagrant@nginx1:~$ echo "<h1>This is NGINX Web Server from Node 1</h1>" | sudo tee /var/www/html/index.nginx-debian.html
Realizamos el mismo procedimiento en el segundo nodo para personalizar su archivo html:
vagrant@nginx2:~$ echo "<h1>This is NGINX Web Server from Node 2</h1>" | sudo tee /var/www/html/index.nginx-debian.html
3. Instalar Keepalived
3.1¿Qué es Keepalived?
Keepalived es una herramienta de software que se utiliza para implementar el VRRP en una red. Funciona enviando mensajes entre los routers que participan en el VRRP para determinar quién es el router activo y quién es el router de respaldo. Si el router activo falla o se desconecta, el router de respaldo toma el control y comienza a enrutar el tráfico de la red.
3.2 Configuración de Keepalived
Procederemos a instalar el paquete Keepalived en ambos nodos para habilitar la configuración de alta disponibilidad.
vagrant@nginx:~$ apt install keepalived
Nodo 1
La configuración de las VRRPs se lleva a cabo mediante el archivo /etc/keepalived/keepalived.conf en ambos nodos.
vagrant@nginx1:~$ sudo vi /etc/keepalived/keepalived.conf
## install yum install gcc kernel-headers kernel-devel
## install yum install keepalived , directory config Keepalived configuration File: /etc/keepalived/keepalived.conf
global_defs {
vrrp_version 3
}
vrrp_script chk_manual_failover {
script "/usr/libexec/keepalived/nginx-ha-manual-failover"
interval 10
weight 50
}
#vrrp_script chk_nginx_service {
# script "/usr/libexec/keepalived/nginx-ha-check"
# interval 3
# weight 50
#}
# Script to check whether Nginx is running or not
vrrp_script check_nginx {
script "/bin/check_nginx.sh"
interval 2
weight 50
}
vrrp_instance VI_1 {
interface enp0s9
priority 100
virtual_router_id 51
advert_int 1
accept
garp_master_refresh 5
garp_master_refresh_repeat 1
unicast_src_ip 192.168.1.32
unicast_peer {
192.168.1.85
}
virtual_ipaddress {
192.168.1.99
}
track_script {
chk_nginx_service
chk_manual_failover
}
notify "/usr/libexec/keepalived/nginx-ha-notify"
}
Ahora vamos a explicar los parámetros esenciales que hemos configurado en el archivo.
Lo primero que hemos configurado es un mecanismo de verificación para determinar si el servicio Nginx se encuentra activo. En caso de que no esté activo, el servicio Keepalived redirige automáticamente el tráfico hacia el nodo de mayor prioridad.
Existen diferentes opciones para crear este script de verificación, como crearlo manualmente o utilizar una librería ya existente como nginx-ha-check. Si optamos por crear el script manualmente, podemos hacer un pequeño script que devuelva el ID del proceso de Nginx.
vagrant@nginx1:~$ sudo vi /bin/check_nginx.sh
#!/bin/sh if [ -z "`pidof nginx`" ]; then exit 1 fi
vagrant@nginx1:~$ sudo chmod 755 /bin/check_nginx.sh
A continuación, configuraremos las instancias VRRP, cada una asociada a una IP virtual diferente, con un nombre único (por ejemplo VI_1) para identificarlas fácilmente.
- Interface: Nombre de la interfaz de red donde tendremos la IP Virtual.
- Priority: La prioridad, siendo 100 la que tiene mayor prioridad y 97 la que tiene menos. En cada máquina le daremos otro número más bajo que el anterior para que la IP virtual tenga prioridad por las primeras máquinas, en caso de caída de ese entorno pasará a la segunda con mayor prioridad (99) y así sucesivamente.
- Unicast_src_ip: IP del nodo donde estamos configurando el Keepalived
- Unicast_peer: Lista de IPs para redirigir el tráfico en caso de caída.
- Virtual_ipaddress: Aquí agregaremos la nueva IP que tendrá la interfaz.
Nodo 2
Vamos a configurar el segundo nodo.
vagrant@nginx2:~$ sudo cat /etc/keepalived/keepalived.conf
## install yum install gcc kernel-headers kernel-devel
## install yum install keepalived , directory config Keepalived configuration File: /etc/keepal>
global_defs {
vrrp_version 3
}
vrrp_script chk_manual_failover {
script "/usr/libexec/keepalived/nginx-ha-manual-failover"
interval 10
weight 50
}
#vrrp_script chk_nginx_service {
# script "/usr/libexec/keepalived/nginx-ha-check"
# interval 3
# weight 50
#}
vrrp_script check_nginx {
script "/bin/check_nginx.sh"
interval 2
weight 50
}
vrrp_instance VI_1 {
interface enp0s9
priority 99
virtual_router_id 51
advert_int 1
accept
garp_master_refresh 5
garp_master_refresh_repeat 1
unicast_src_ip 192.168.1.85
unicast_peer {
192.168.1.32
}
virtual_ipaddress {
192.168.1.99
}
track_script {
chk_nginx_service
chk_manual_failover
}
notify "/usr/libexec/keepalived/nginx-ha-notify"
}
La configuración del segundo nodo es parecida, pero tenemos que cambiar un par de parámetros.
- Es necesario establecer un número de prioridad menor en comparación con el primer nodo en el cluster.
- Modificaremos la configuración de la opción unicast_src_ip, estableciendo como valor la dirección IP de este nodo.
- Finalmente, actualizaremos la lista de direcciones IP en la opción unicast_peer agregando la dirección IP del primer nodo en el cluster, ya que en este escenario solo contamos con dos nodos. En caso de caída de este nodo, el control del cluster automáticamente se trasladará al primer nodo si este se encuentra activo.
4. Activación del servicio de Keepalived y comprobaciones del cluster
Una vez configurados ambos nodos, solo nos queda activar el servicio de Keepalived y realizar las comprobaciones necesarias para garantizar que el cluster está funcionando correctamente.
Con el servicio Keepalived activo, procederemos a realizar las comprobaciones necesarias para asegurarnos de que el cluster está funcionando correctamente. Para ello, ejecutaremos el comando ‘ip a’ para verificar la lista de direcciones IP y comprobar si la dirección IP virtual se ha agregado correctamente a nuestra interfaz de red.
vagrant@nginx1:~$ sudo systemctl start keepalived
vagrant@nginx2:~$ sudo systemctl start keepalived
vagrant@nginx1:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 02:de:e5:0c:c2:13 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic enp0s3
valid_lft 86259sec preferred_lft 86259sec
inet6 fe80::de:e5ff:fe0c:c213/64 scope link
valid_lft forever preferred_lft forever
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:b1:9d:28 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.4/24 brd 192.168.56.255 scope global enp0s8
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feb1:9d28/64 scope link
valid_lft forever preferred_lft forever
4: enp0s9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:14:00:bd brd ff:ff:ff:ff:ff:ff
inet 192.168.1.32/24 brd 192.168.1.255 scope global dynamic enp0s9
valid_lft 86260sec preferred_lft 86260sec
inet 192.168.1.99/32 scope global enp0s9
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe14:bd/64 scope link
valid_lft forever preferred_lft forever
Con el servicio Keepalived activo, procederemos a realizar las comprobaciones necesarias para asegurarnos de que el cluster está funcionando correctamente. Para ello, ejecutaremos el comando ‘ip a’ para verificar la lista de direcciones IP y comprobar si la dirección IP virtual se ha agregado correctamente a nuestra interfaz de red.
Como se puede observar, la dirección IP 192.168.1.99 se ha agregado correctamente a la interfaz enp0s9 que configuramos. Realizaremos la misma verificación en el segundo nodo del cluster para asegurarnos de que se ha agregado correctamente.
vagrant@nginx2:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 02:de:e5:0c:c2:13 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic enp0s3
valid_lft 86286sec preferred_lft 86286sec
inet6 fe80::de:e5ff:fe0c:c213/64 scope link
valid_lft forever preferred_lft forever
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:92:f3:d0 brd ff:ff:ff:ff:ff:ff
inet 192.168.56.5/24 brd 192.168.56.255 scope global enp0s8
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe92:f3d0/64 scope link
valid_lft forever preferred_lft forever
4: enp0s9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:2c:4a:24 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.85/24 brd 192.168.1.255 scope global dynamic enp0s9
valid_lft 86287sec preferred_lft 86287sec
inet6 fe80::a00:27ff:fe2c:4a24/64 scope link
valid_lft forever preferred_lft forever
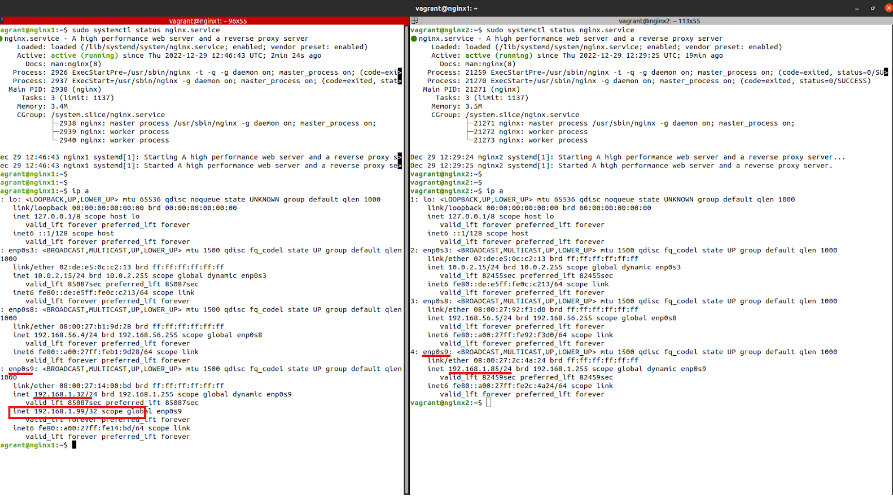
Figura 2. Comprobaciones
En este nodo, no encontraremos la dirección IP virtual, ya que solamente puede existir en un solo nodo, el nodo activo en el cluster. De esta manera, podemos realizar una comprobación haciendo una petición web a la dirección IP virtual para verificar que el primer nodo está respondiendo correctamente.

Figura 3. Petición web
El nodo 1 está respondiendo correctamente, como se puede verificar.
Para demostrar cómo funciona la failover, detendremos el servicio Keepalived en el nodo 1, lo que hará que la IP virtual se transfiera al segundo nodo y el tráfico sea redirigido a esta máquina.
vagrant@nginx1:~$ sudo systemctl stop keepalived
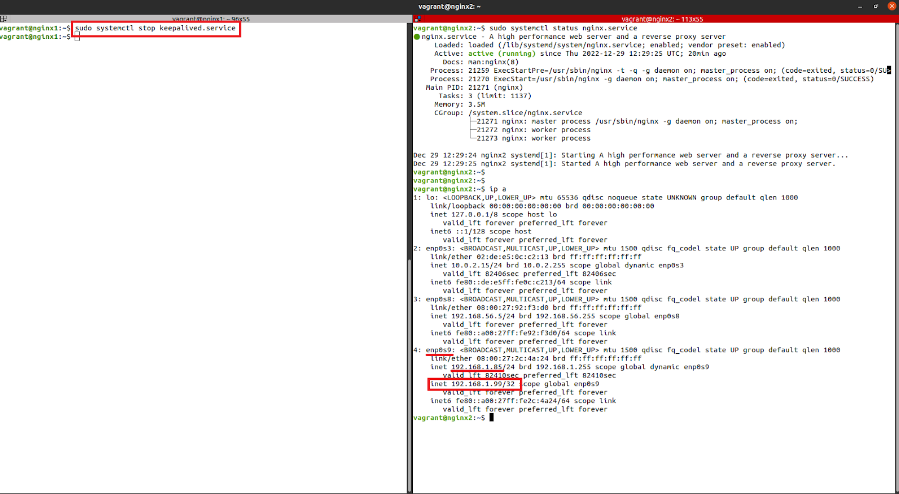
Figura 4. Keepalived en el nodo 1
La IP virtual se ha trasladado correctamente al segundo nodo, como se puede verificar. Si realizamos una comprobación vía web, podemos observar que el nodo 2 está respondiendo correctamente.
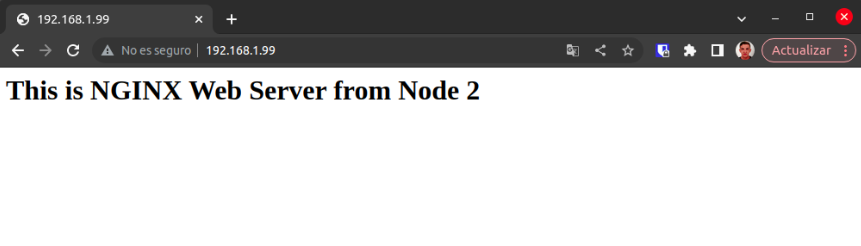
Figura 5. Petición Web Node 2
5. Activar/Desactivar Keepalived
En caso de que necesitemos desactivar o activar el keepalived para que la IP Virtual se ponga en las otras máquinas solamente tendremos que desactivar el keepalived. Esto se puede hacer mediante el comando ‘systemctl stop keepalived.service’ en la consola de los load balancers.
Además, se puede automatizar este proceso mediante una tarea de Jenkins configurando parámetros, lo que permite realizar esta acción de manera más sencilla y sin tener que acceder a las máquinas manualmente.
Figura 6. Activar / Desactivar Keepalived
De esta forma, se tiene la facilidad de redirigir el tráfico hacia otro nodo con solo un clic, lo que es útil para realizar mantenimiento en uno de los nodos sin interrumpir los servicios. Esto se logra sin necesidad de reiniciar.
6. Conclusión
Keepalived es una plataforma con un gran poder para el balanceo de carga y mantener en Alta Disponibilidad los servicios en red, sencilla de configurar y cómoda de instalar, al estar compilado y empaquetado en los repositorios de la mayoría de distribuciones de linux.
Gracias al laboratorio que hemos montado hemos podido ver una de las muchas opciones que nos ofrece tener nuestra infraestructura con este tipo de configuración. Y de la mano de Chakray Consulting tendrás un apoyo y desarrollo profesional en este tipo de software para Alta Disponibilidad. No dudes en contactar con nosotros, aquí.





